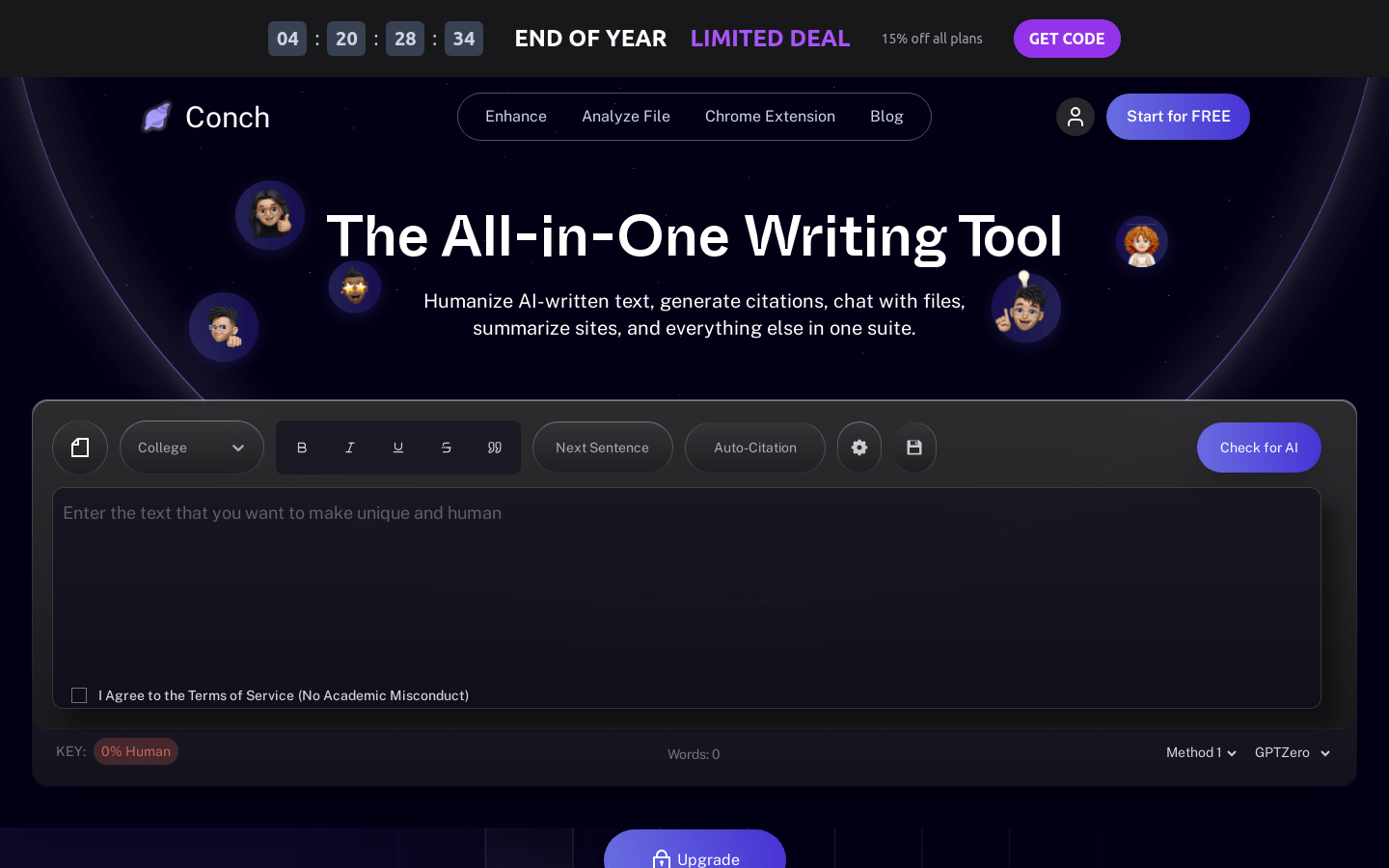
Conch是一款一站式写作工具,通过人性化AI文本生成,引用生成,文件对话,网站摘要等功能,让用户能够以更快的速度写作。其优势在于能够帮助用户以更快的速度写作,并且能够通过AI技术绕过GPTZero、Turnitin、Originality等检测器,保护用户的隐私。Conch提供免费计划和付费计划,付费计划分为Conch Classic、Conch Pro和Conch Limitless,分别提供不同的字数限制和功能。此外,Conch还提供Chrome插件,用户可以在浏览器中快速使用Conch的功能。
需求人群:
"Conch适用于需要提高写作效率、保护隐私、快速获取文本摘要的用户,特别适合学生、研究人员和写作者。"
使用场景示例:
学生可以使用Conch加快写作速度,并绕过学术检测器保护隐私。
研究人员可以利用Conch快速获取文献摘要,提高工作效率。
写作者可以使用Conch自动补全句子,从而避免创作困难。
产品特色:
以更快的速度写作
通过AI技术绕过检测器,保护用户隐私
文件对话功能
网站摘要功能
引用生成功能
自动补全句子
模板应用
快速回答问题
文本摘要
浏览量:112
最新流量情况
月访问量
76.18k
平均访问时长
00:00:12
每次访问页数
3.41
跳出率
40.56%
流量来源
直接访问
32.99%
自然搜索
55.87%
邮件
0.17%
外链引荐
7.20%
社交媒体
2.78%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
巴西
8.73%
印度尼西亚
5.84%
印度
5.45%
秘鲁
4.60%
美国
20.48%
AI辅助写作工具,提供多种写作辅助功能。
柒源写作是一个基于AI技术的在线写作辅助平台,旨在通过人工智能技术提高写作效率和质量。它提供了包括AI对话、降重复率、一键生成文章、一键生成图表等多种功能,帮助用户快速完成写作任务。产品背景信息显示,柒源写作注重用户体验,提供免费试用和多种付费服务,定位于帮助用户提升写作效率,降低写作难度。
AI 助力全流程让写作更轻松
光速写作是一款智能写作软件,为学生及职场人士提供全文生成、大纲生成、文章改写、续写、扩写等多种功能。通过 AI 技术,根据用户的需求自动生成文本,大幅提升写作效率。光速写作支持跨平台云存储,多端同步编辑查看,自动保存永不丢失。
一站式写作工具,人性化AI文本生成,引用生成,文件对话,网站摘要等
Conch是一款一站式写作工具,通过人性化AI文本生成,引用生成,文件对话,网站摘要等功能,让用户能够以更快的速度写作。其优势在于能够帮助用户以更快的速度写作,并且能够通过AI技术绕过GPTZero、Turnitin、Originality等检测器,保护用户的隐私。Conch提供免费计划和付费计划,付费计划分为Conch Classic、Conch Pro和Conch Limitless,分别提供不同的字数限制和功能。此外,Conch还提供Chrome插件,用户可以在浏览器中快速使用Conch的功能。
快速生成各种文本和复制的免费AI写作工具
AI Writer是一个强大的AI写作工具,可以帮助用户快速生成各种文本内容。它提供了多种功能,包括生成商业计划、写博客、生成创意故事、重写段落等。AI Writer的优势在于能够节省用户的时间和精力,提高写作效率。它的定价分为免费、付费、免费试用和免费增值等不同选项。
AI辅助写作工具
AllWrite是一款AI辅助写作工具,通过最新的人工智能技术生成写作思路、建议和反馈,帮助用户创作高质量内容。无论是邮件、博客、论文还是网站内容,AllWrite的内容生成工具和文章生成器都可以帮助用户创作独特且引人入胜的作品。适用于博主、作家以及任何想提高写作技巧的人群。立即尝试AllWrite,体验AI写作的强大之处!
一款功能全面的 AI 智能写作工具。
蛙蛙写作是一款集创意灵感获取、小说改编、视频生成等多种功能于一体的智能写作助手。它帮助用户高效创作,适用于学术、职场及个人项目。产品背景强大,定位于提升写作效率,适合各类创作者。
一款支持一键生成论文、PPT、开题报告的AI系统,具备AIGC降重功能,适合学术写作。
该产品是一款基于AI技术的论文生成系统,能够快速生成高质量的学术论文、PPT和开题报告,并支持AIGC降重功能。其主要优点包括高效生成、降重稳定、文献真实可查等。产品定位为学术写作辅助工具,适用于高校学生、研究人员和教育机构。
AI辅助写作
Simpler.ai是一款AI辅助写作工具,使用AI技术提供简单、高效的写作体验。它能帮助用户撰写内容、提供写作建议、完成列表等。拥有无干扰的用户界面,类似于Google Docs的编辑器,支持多语言,并提供Dark Mode。早期注册用户可获得6000个免费积分和免费的Grammarly拼写检查。
AI驱动,帮助写作和内容创作
小鱼AI写作是一个AI驱动的写作辅助平台,提供3958个精品AI写作模板,满足不同场景的使用需求。该平台特别适合0基础用户,可以在1分钟内轻松完成写作任务,激发写作灵感,帮助用户更好地表达思想。功能包括AI文章创作、AI续写、文章润色等。
内容创作 AI 辅助工具
Giiso 写作机器人是一款内容创作 AI 辅助工具,提供热点写作、提纲写作、汽车写作等类型写作,具备智能写作、智能推荐素材、稿件改写、稿件查重、稿件纠错等功能。Giiso 写作机器人是自媒体、新媒体写作的好帮手。Giiso 写作机器人的优势包括智能推荐素材和稿件改写功能,能够提高写作效率和稿件质量。Giiso 写作机器人的定价根据用户需求而定,详情请咨询客服。
AI辅助写作工具
Reword是一款AI辅助写作工具,帮助团队合作创作出优秀的文章。它基于读者训练的AI编辑器,提供了一系列工具,让您能够撰写出表现出色的内容。Reword能够了解您的读者,帮助您团队高效协作。
AI 写作系统
悟智写作是一款全面的 AI 写作辅助工具和智能助手,通过大模型技术的驱动,为您开启全新的写作体验。它提供智能写作、智能对话、AI 绘图等功能,帮助用户快速创作高质量的文本内容。悟智写作适用于各类写作场景,如文案创作、论文写作、写作指导等。您可以通过悟智写作网页版、悟智小程序、悟智 App 等多个形态进行使用。悟智写作免费注册,付费会员用户享受更多高级功能和优质服务。
智能AI辅助小说创作工具
AI小说生成器是一个专为小说创作者设计的智能AI辅助工具,它通过提供各种写作模板、灵感词库、人物设定、剧情生成等功能,帮助作者快速构思和创作小说。该产品背景信息显示,它由上海简办网络科技有限公司开发,旨在解决作者在创作过程中遇到的灵感枯竭、写作效率低下等问题。产品的主要优点包括丰富的写作模板、AI智能生成和改写功能、以及对不同小说类型的全面支持。价格方面,产品提供终身会员服务,每月只需极低的费用,性价比极高。
AI辅助写作工具
EZAi是一款AI辅助写作工具,旨在让用户轻松创作引人入胜的内容。无论是在办公桌前还是在外出时,都可以轻松创建出引人注目的内容。EZAi拥有12个内置的AI助手,帮助您的业务蓬勃发展。通过EZAi,您可以尽情发挥创造力,利用超过60种专业设计的模板,轻松打造出卓越的内容。
AI辅助写作工具
QuillGenius是一款AI辅助写作工具,帮助用户快速生成高质量的内容。通过使用QuillGenius,您可以节省时间,提高写作质量,吸引受众并促进转化。QuillGenius可以用于博客、社交媒体和其他写作任务,提供90多个模板供您选择,帮助您节省时间并提升写作技巧。
AI写作工具,提升写作效率
Brisk Write是一款AI写作工具,可以帮助用户快速写作论文、研究报告等各种文档。它具有智能的编辑界面和支持性的人工智能,可以帮助用户组织思路,加速写作过程。用户可以提高文章质量,同时减少对截止日期的压力。Brisk Write得到全球许多用户的认可。
AI写作助手,帮助您更高效地撰写文本
Promptist是一款AI写作助手,通过为用户提供优质的文本生成模型,帮助用户更高效地撰写各种文本内容。Promptist具有以下特点和优势: 1. 强大的文本生成能力:Promptist基于最新的自然语言处理技术,能够生成高质量、流畅的文本内容。 2. 多种写作场景支持:Promptist可以应用于各种写作场景,包括新闻报道、科技文章、商业文案等。 3. 个性化定制:用户可以根据自己的需求定制生成模型,以获得更加符合自己风格的文本内容。 4. 简单易用的界面:Promptist提供简洁易用的用户界面,让用户可以轻松使用和操作。 Promptist的定价和定位请参考官方网站。
高质量AI毕业论文写作平台
66论文AI写作4.0版是一个专注于学术写作辅助的在线平台,提供从毕业论文到期刊论文等多种学术文档的AI辅助写作服务。该平台利用先进的人工智能技术,帮助用户快速生成论文大纲、正文内容,同时支持多种学科和语言,确保写作的严谨性和规范性。平台还提供文献综述、摘要、致谢等模板,以及查重率控制服务,满足学术写作的高标准需求。
Ai写作助手,支持论文、文案、策划等文字创作
面向专业写作领域的多场景AI写作工具,能免费生成AI文案,操作简单,无任何使用门槛。写作场景包括论文大纲、公文写作、商业计划书、自媒体创作、营销内容和生活娱乐内容等。除了一键生成文案,它还支持智能续写、改写文稿,只需上传文档或输入内容。你还可使用免费AI对话、专家对话等功能进行答疑解惑、趣味聊天。
AI辅助写作工具,提升研究论文撰写效率。
SciSpace AI Academic Writer是一个AI辅助写作工具,旨在帮助用户在撰写研究论文时提高效率和质量。它通过提供自动引用、思想自动完成、笔记保存和无损失格式导出等功能,使研究写作变得更加便捷。SciSpace是该产品的技术支持方,它通过AI技术简化和解释学术论文中的复杂文本,帮助用户更好地理解和撰写研究内容。
AI写作工具箱,实时提供写作建议
Bettertext是一款基于OpenAI ChatGPT API技术的AI写作工具箱。它能实时分析文本,并即时提供改进建议。用户可以根据自己的写作风格和需要选择合适的语气,帮助提升专业性或对话性。该工具箱提供了多种功能,包括改进和重写文本、缩短文本、扩展文本、继续写作、邮件和消息回复、问题回答、摘要、翻译等。它适用于学生、专业人士和内容创作者等任何需要高效写作的人群。
一键生成论文、邮件等,提升写作效率。
有道翻译·AI写作是一款旨在提高写作效率和内容质量的在线工具。它支持一键生成论文、邮件、公文通知、营销文案等,同时提供润色、扩写、总结、去重等高级功能。该产品支持100多种语言,通过多端同步技术,用户可以在不同设备上继续之前的工作,保证了数据的安全性和创作的连续性。
AI智能生成写作大纲,快速为您生成论文大纲
轻创AI写作系统是一款AI智能生成写作大纲的在线平台。它可以根据用户输入的论文关键词,快速生成包括标题、章节等在内的完整论文大纲。该系统具有操作简单、智能生成、节省时间等优势,适用于期刊论文、科普文章、毕业论文、商业报告等多种写作场景,可以高效辅助用户进行学术和商业写作。
基于AI的辅助论文写作工具
SOM AI是一个基于人工智能的辅助论文写作工具,帮助用户轻松撰写论文。它提供实时支持和建议,帮助用户在论文撰写过程中解决问题。SOM AI还具有智能聊天功能,可以作为用户的论文伴侣,提供轻松愉快的论文写作体验。
智能公文写作助手,一键生成高效办公。
讯飞公文写作是科大讯飞推出的一款专注于公文写作的人工智能服务,旨在通过大模型技术辅助用户快速生成各类公文材料。产品背景依托科大讯飞在智能语音和人工智能领域的深厚积累,具有高效、保密、素材丰富等特点,适用于政府机关、企事业单位等需要撰写公文的用户。
SEO 友好的 AI 写作生成器
智能写作助手利用人工智能来辅助进行 SEO 写作。我们的 AI 文章生成器可以生成博客大纲 / 博客标题 / 博客引言 / 博客创意,扩展文章大纲,修改语言,改写或总结文本,生成摘要,增强句子结构等功能。我们的 AI 写作生成器简单易用,可定制化,生成高质量内容,价格实惠。
AI写作工具,克服写作困难,提升学术写作水平。
AI Essay Writer是一款基于人工智能的写作工具,可以帮助学生快速生成结构良好、引用丰富的论文内容。它利用长期机器学习的方法,通过收集和分析高质量的学术论文样本,生成具有创意和新颖观点的论文。AI Essay Writer还具有以下功能和优势: 1. 生成的论文包含科学资源的引用,符合学术要求。 2. 可以自动格式化论文,支持APA和MLA格式。 3. 用户可以通过描述区域影响论文的风格和语气。 4. 提供使用示例,帮助用户理解高质量的写作风格。 AI Essay Writer是针对学生和学者的写作工具,帮助他们克服创作障碍,提高学术写作水平。 定价:免费使用。 使用场景:学术写作、论文撰写、创作灵感获取。 标签:AI写作、学术写作工具、论文生成器。

© 2026 AIbase 备案号:闽ICP备08105208号-14