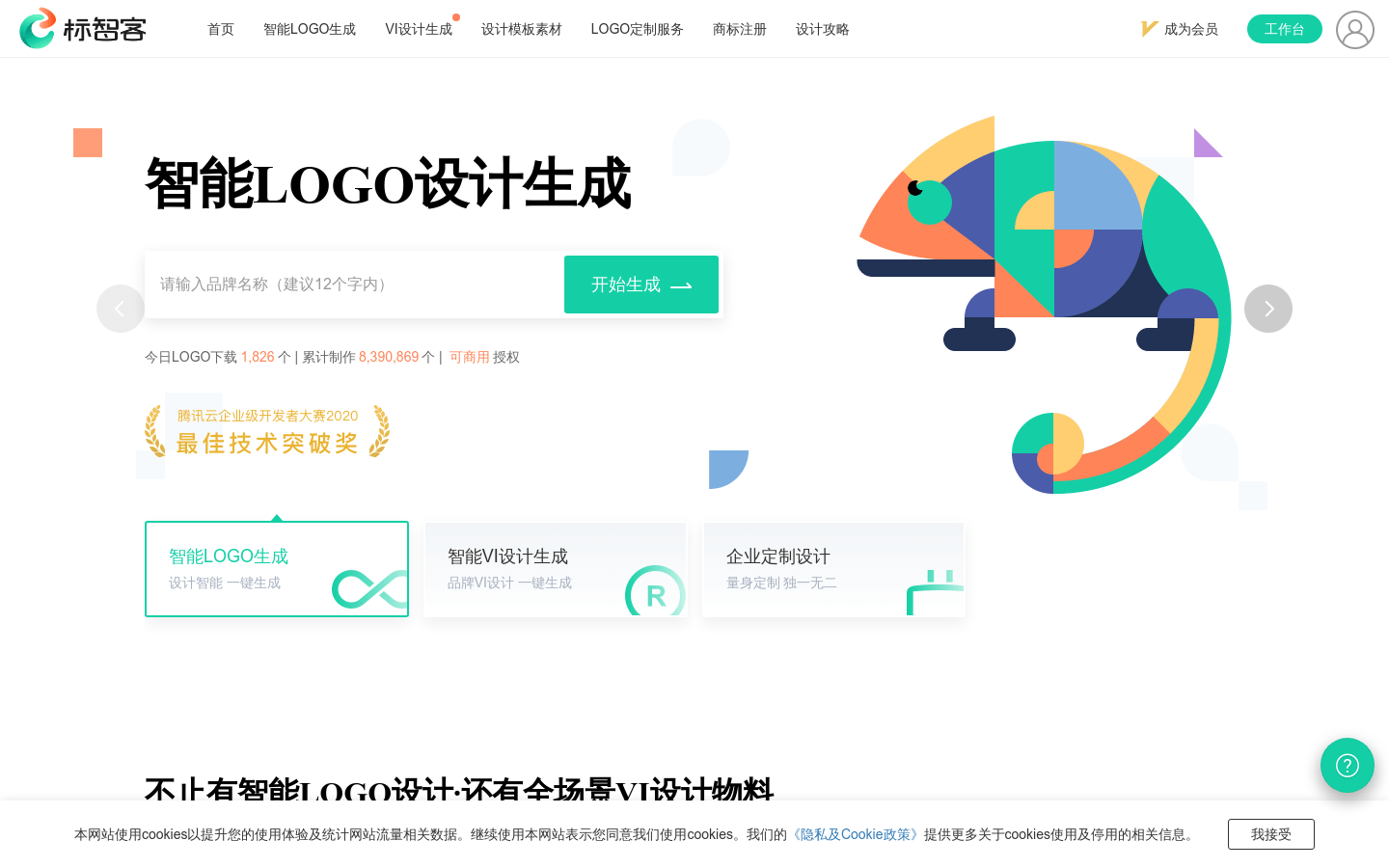
标智客是一款免费在线Logo设计生成工具,使用AI智能技术,可以一键生成个性化的公司Logo、品牌VI设计。用户只需输入品牌名称,标智客就可以在1分钟内生成适合该品牌风格的Logo设计素材,并提供多种格式的设计源文件免费下载使用。平台Logo设计模板丰富,智能生成效果专业,定制灵活,商业授权可靠,是中小企业品牌VI设计的优选解决方案。
需求人群:
["中小企业品牌VI设计","创业公司Logo制作","个人品牌Logo设计"]
使用场景示例:
创业公司可以在标智客快速生成适合自身品牌风格的Logo
个人博主可以使用标智客一键生成个性化的Logo素材
中小企业可以免费下载标智客自动生成的Logo设计源文件
产品特色:
智能一键生成Logo设计
支持AI智能学习用户偏好
提供多种设计模板和素材
Logo设计可免费商用
设计源文件多格式免费下载
浏览量:383
最新流量情况
月访问量
102.97k
平均访问时长
00:02:19
每次访问页数
4.30
跳出率
27.14%
流量来源
直接访问
32.89%
自然搜索
62.38%
邮件
0.03%
外链引荐
4.14%
社交媒体
0.45%
展示广告
0
截止目前所有流量趋势图
地理流量分布情况
中国
87.92%
日本
1.18%
美国
1.46%
免费在线AI Logo生成器,几秒生成专业Logo,无需设计经验。
AI Logo Generator是一款基于智能AI技术的在线Logo生成工具。其重要性在于为各类创作者和品牌提供了便捷、高效且经济的品牌设计解决方案。主要优点包括由AI驱动设计,能生成独特且个性化的Logo;免费且在线可用,无需下载复杂工具;可轻松自定义字体、颜色等;能即时下载高分辨率图像。该产品面向自由工作者、创业公司等有品牌设计需求的群体,完全免费使用,定位是为不同用户提供快速、优雅的品牌设计服务。
免费在线 AI Logo 创建工具,几分钟生成专业 logo,适合各类品牌。
Logo 创建器是一款由 AI 驱动的免费在线工具,无需下载软件。其重要性在于让用户能快速、便捷地设计出专业 logo。主要优点有免费使用、AI 快速生成独特概念、可轻松自定义。该产品面向企业、初创公司和个人品牌,旨在帮助各类创作者和专业人士打造时尚、个性的品牌形象。
超级智能好用的 Logo 在线设计生成器
LOGO123 是一款超级智能好用的 Logo 在线设计生成器,为您提供免费公司 logo 设计制作。只需输入品牌名称就能免费在线生成公司 logo 设计及配套企业 VI,轻松打造您的个性品牌!我们还提供配套名片、企业 VI、专业出品、版权可商用等服务,帮助您打造完整的品牌形象。
免费在线生成个性化Logo设计
标智客是一款免费在线Logo设计生成工具,使用AI智能技术,可以一键生成个性化的公司Logo、品牌VI设计。用户只需输入品牌名称,标智客就可以在1分钟内生成适合该品牌风格的Logo设计素材,并提供多种格式的设计源文件免费下载使用。平台Logo设计模板丰富,智能生成效果专业,定制灵活,商业授权可靠,是中小企业品牌VI设计的优选解决方案。
ChatGPT LOGO是一款AI Logo生成器,快速、智能,适用于任何品牌。
ChatGPT LOGO是一款由ChatGPT驱动的AI Logo生成器,用户可以快速生成定制化的Logo设计。该产品具有智能生成、高效快速、适用广泛的优点,背景信息为ChatGPT技术支持,定位于为用户提供优质Logo设计解决方案。
AI大数据一键设计LOGO
一键Logo设计是一款基于AI大数据计算的智能设计生成器,只需简单输入名称口号,选择行业偏好,即可一键生成LOGO。所有元素均可调整修改,多种格式文件均可下载导出。一次购买长期使用,各种模板字体均可商用。适用于需要快速生成LOGO的个人、企业、团队等用户。
AI 工具快速生成独特 logo 设计。
Any Logo Generator 是一个基于人工智能的 logo 生成工具,用户可以选择喜欢的设计,或上传自己的设计,以快速生成独特的 logo。该产品的主要优点是能够在几秒钟内为品牌打造完美的 logo,适合各种用户,尤其是创业者和小型企业主。产品定位于简化 logo 设计过程,提高设计效率。该工具目前免费提供使用。
专业LOGO设计服务平台
LOGO123是一个提供专业LOGO设计服务的平台,它利用人工智能技术为用户设计个性化的LOGO,并通过设计师PK的方式为用户挑选出最佳的设计方案。该平台支持在线提交设计需求,用户可以选择多种套餐服务,包括LOGO设计、品牌VI设计、广告海报设计以及商标注册等。LOGO123致力于为用户提供高品质、全方位的品牌设计服务。
免费在线制作人工智能logo
Artificial Intelligence Logo Maker提供了许多新的想法,帮助您在线创建logo设计。选择可定制的模板,释放您的灵感,开发符合您需求的人工智能logo设计。借助人工智能logo制作工具,您可以更轻松地享受永久的质量和设计功能。该工具提供了多种人工智能logo模板,您可以根据自己的需求进行定制。制作完成后,您可以下载自定义的人工智能矢量logo图像,并更新所有资产以使用新的logo。
唯一的定制Logo,只属于你
Crunchy Logo是一个提供定制Logo的平台。我们提供独一无二的Logo设计,每个Logo只会售出一次,确保你拥有独享的权利。我们的Logo设计简洁、优雅,能够满足各种品牌形象的需求。无论你是个人还是企业,Crunchy Logo都能帮助你打造一个与众不同的品牌形象。定价根据Logo的复杂程度和使用范围而定。我们的目标是为你提供高质量的Logo设计,帮助你脱颖而出。
利用生成式人工智能在几秒钟内创建独特和定制的Logo
Logo Diffusion是一款利用生成式人工智能来创建独特和定制的Logo的设计工具。用户可以通过文字提示、现有Logo或简单草图,快速生成符合自己需求的Logo设计。产品还提供2D转3D、图像转2D等功能,帮助用户实现品牌形象的多样化。Logo Diffusion定位于为用户提供简单、高效的Logo设计解决方案。
免费的Logo制作工具
Adobe Express Logo Creator是一款免费的Logo制作工具,用户可以通过输入品牌或商业名称、选择喜欢的风格、图标和字体等,快速生成高质量的Logo。该工具还提供了丰富的动画效果和字体推荐功能,用户可以在在线编辑器中进一步定制Logo,并将其下载为高质量的PNG和JPG文件,方便在各种平台上使用。
在线生成个性化logo的平台
Logo-creator.io是一个在线平台,用户可以通过简单的操作生成个性化的logo。该平台利用Together.ai和Flux的技术,提供了多种风格和颜色选项,使得用户可以快速创建出符合自己公司或品牌风格的logo。它的重要性在于简化了logo设计的流程,使得非专业设计师也能轻松创建出专业的logo,这对于初创企业和个人品牌尤为重要。该平台提供免费账户创建和logo生成服务,定位于为中小企业和个人提供便捷的设计解决方案。
用AI在几秒钟内制作原创Logo
Spacelogo是一个AI Logo生成器,可以帮助您快速创建符合品牌个性和价值观的专业Logo设计。您可以免费生成Logo,也可以选择付费版本以获得更高分辨率的文件和更多的自定义选项。Spacelogo适用于需要专业Logo设计的企业、网站和个人。
AI设计师专业logo设计
HidingElephant是专为专业设计师打造的最佳AI Logo设计工具。它可以根据简单的提示生成定制、独特的Logo,每次都能获得不同的结果。未来的Logo设计之选。
使用AI生成创意Logo概念的免费在线工具,帮助您为品牌或业务构思Logo设计。
LogoCue是一个利用人工智能生成创意Logo概念的在线工具,用户只需描述品牌,AI便能提供独特Logo概念。LogoCue帮助用户快速获得高质量的Logo设计,无需设计技能。
AI助力创意设计,激发灵感
IMAGIX是一款AI助力创意设计的工具。它能够生成引人入胜的设计、独特的插图和引人入胜的内容,轻松激发创意过程,将您的作品提升到新的高度。探索无尽的可能性,自信地创作。立即尝试我们的AI工具!
免费创建精美的 AI Logo
DesignEvo是一款由PearlMountain有限公司设计研发的logo设计软件。这款软件提供大量可编辑的模板,可以帮助你轻松做出精美的AI logo。无需任何logo设计经验!如果你的业务与人工智能有关,那么你可以在这里找到一些灵感并设计精美的AI logo。在制作AI logo时,一般都会使用大脑和电路图标等元素。现在就挑选一个喜欢的模板,然后选择适合的图标、字体和编辑功能来制作你的logo吧!
专业的智能AI商标logo设计平台
U钙网是一个专业的智能AI商标logo设计平台,提供给用户一个简单易用的在线设计工具,无论用户是否具备设计背景,都可以通过输入文字自助设计出专业、精美的LOGO标志。平台拥有十几年的专业专注智能LOGO设计经验,服务用户已超千万,遵循标志logo设计理念的艺术规律,创造性地探求恰当的艺术表现形式和手法,确保所设计的标志logo具有高度的整体美感和最佳视觉效果。
AI生成logo
LogoStoreAI是一款AI生成logo的平台,通过AI技术生成独特的logo和图像素材,帮助企业提升品牌形象。用户可以选择AI生成的logo或使用SVG logo制作工具创建自己的logo。LogoStoreAI提供1024x1024高清logo及其他多种尺寸的logo包,包括favicon图标(48x48)、Android商店图标(512x512)和Apple应用商店图标(1024x1024)。该平台还提供了多种使用场景,包括提升品牌在社交媒体上的存在、物理世界的品牌展示、商业卡片设计等。用户可以通过LogoStoreAI轻松创建具有品牌特色的logo,并在不同场景下展现品牌形象。
AI设计,一键生成个性化Logo。
AI Logo Designs Gallery是一个在线平台,利用人工智能技术为用户提供个性化的Logo设计服务。用户只需输入品牌名称和一些基本的设计要求,AI即可生成多种风格的Logo供选择。该平台支持多种行业和风格,包括极简、中等复杂度等,满足不同用户的需求。
在线AI Logo制作,快速生成个性化标志。
Logo Galleria是一个在线AI Logo制作平台,利用人工智能技术帮助用户快速生成个性化的标志设计。它通过用户输入的行业、风格等参数,提供定制化的标志设计方案,满足不同用户的设计需求。该平台的主要优点是操作简便、设计效率高,可广泛应用于品牌建设、产品包装等场景。
人工智能在线LOGO设计,打造个性品牌!
标小智LOGO神器是一款基于设计原理、历史数据和用户操作等多方数据源的AI原创方案,提供矢量、反色、黑白、透明等10多种LOGO文件格式在线输出。同时,提供LOGO字体商用授权,一次购买永久授权。作为智能品牌创建平台,标小智LOGO神器还将为您的LOGO定制生成配套名片、企业VI、宣传海报、社交应用等全套的品牌资源,助您轻松实现品牌自动化!
LogoZanaat是一个可以快速设计简单独特logo的工具。
LogoZanaat是一个免费且易于使用的工具,用于快速设计简单独特的logo。它适用于初学者和专业人士,主要优点在于操作简单、免费使用、适合各种用户需求。
AI创意logo壁纸定制
LogoScapes是一款利用人工智能技术定制logo壁纸的网站。用户可上传自己的logo,通过AI滤镜生成5款精美壁纸,支持社交媒体、封面图片等多种应用场景。定价为30美元,适合个人和企业用户。
一站式的专业Logo设计解决方案
Logomaster.ai是一站式的专业Logo设计解决方案。用户可以轻松创建和编辑Logo,无需设计技能。使用Logomaster.ai,您可以在5分钟内获得专业Logo设计,而不是几天。我们提供多种定价方案,让您根据需求选择合适的方案。
独特的AI Logo Maker,轻松制作独特的Logo
使用Tailor Brands的AI Logo Maker轻松创建独特的Logo设计。我们的Logo设计都是独一无二的,没有预先制作的模板!免费试用。 主要功能: - 提供个性化的Logo设计 - 选择不同的Logo样式 - 自定义Logo设计元素 - 提供高分辨率的Logo文件 - 支持社交媒体格式 - 提供品牌资产和客户支持 定价:免费试用,付费计划根据需求定价。 适用场景:适用于任何需要独特Logo设计的个人、企业和品牌。 标签:Logo设计、品牌标识、创意设计

© 2026 AIbase 备案号:闽ICP备08105208号-14